1. 实例网站及要求
目标网址:263作文网高一作文部分(http://www.263y.com/gaozhong/gaoyi/)。
下载要求:下载作文内容页的作文标题和作文内容字段。
2. 配置步骤
- 新建任务
在平台上新建任务,配置相应的英文名称,中文名称,分类,以及任务组这些基本信息,相关名词解释已在前面说明,在起始url中配置所要爬取网站的链接,然后在其他设置里面我们要习惯性的更改网页的编码格式以及设置UA,查看网页编码格式如下图所示
通过这样在360浏览器里面进行编码查看便可以快速的查看网页编码,下面我们开始进行爬虫列表页以及内容页的操作。
- 解析配置:网页采集规则
当我们进入列表页配置的时候,要知道列表页的链接是从起始url中来的,第一步配适配于起始url的正则,我们的起始url是http://www.263y.com/gaozhong/gaoyi/,
这里我们可以http://www.263y.com/\w+/\w+/$这个作为正则规则,具体正则请看相应文档查阅,我们在配置提取url这块时,要选择xpath,也可以选择自动提取,自动提取下面有三个属性,分别对应提取所有url,相同域链接,以及url正则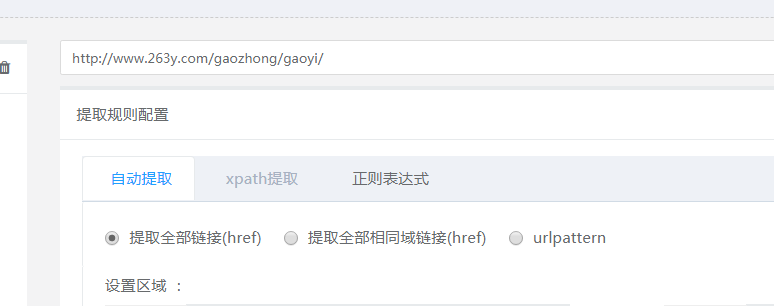
在这里我们选择的xpath提取方式,通过下图分析
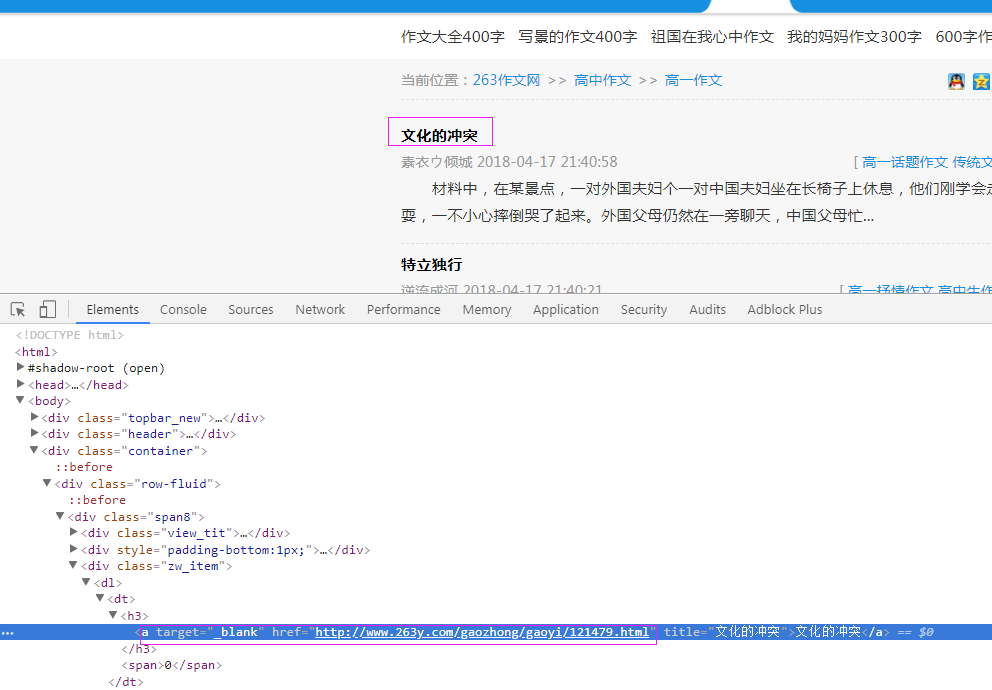
我们获取了本页的作文链接的所在路径
//div[@class="zw_item"]/dl/dt/h3/a/@href
到目前为止,我们还无法实现获取下一页的链接的这个功能,为找到这个入口,我们从网页中寻找到下图
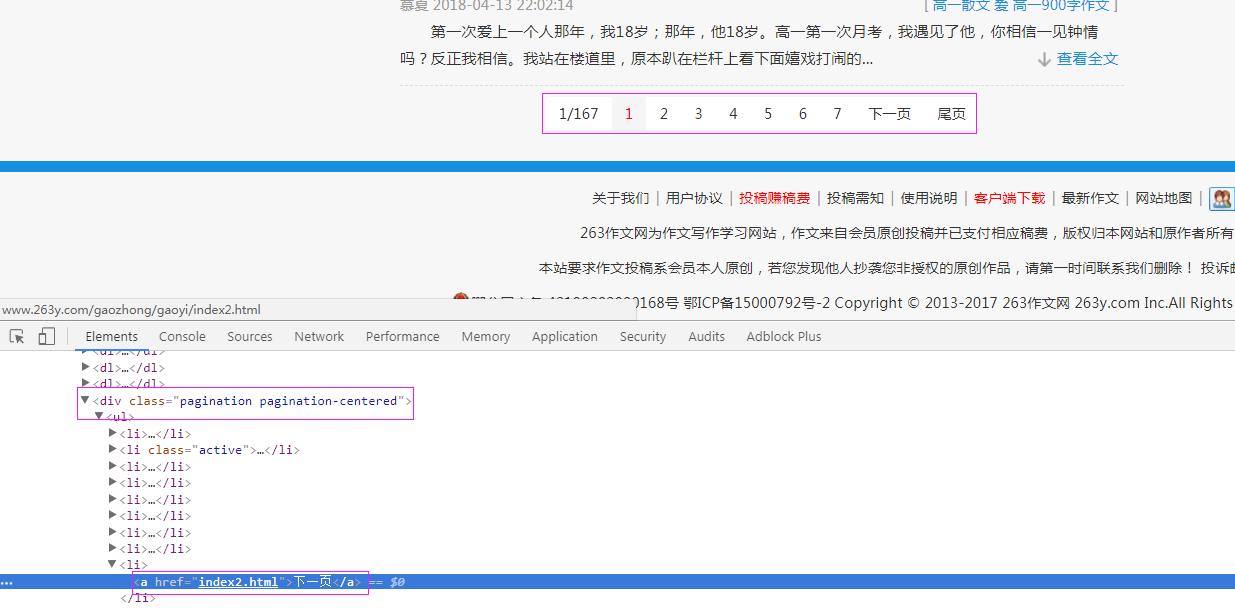
通过如图所示框架,我们可以配置这样的xpath提取规则
//div[@class="pagination pagination-centered"]/ul/li/a/@href
将这两个xpath规则用‘|’连接,我们便实现了在列表页获取作文链接已经下一页的链接,那么接下来我们开始配置内容页的相关信息。
- 解析配置:内容采集规则
点开具体的一篇作文,我们在这里要提取的是标题,以及正文,回到平台内容页配置
点击内容页解析配置列表后面的‘+’,弹出内容页配置有关信息,填写好一些基本信息,在这里要为这个内容页也配置一个正则,以http://www.263y.com/gaozhong/gaoyi/121479.html为例,我们可以看到,当点开不同的作文范文页面时,变化的是121479这6位数字组成的id,所以在这里配置正则时只需要http://www.263y.com/gaozhong/gaoyi/\d+.html即可,到这里进行的就是具体字段的配置了

点击‘+’,配置字段名英文名称,中文名称,以及描述,
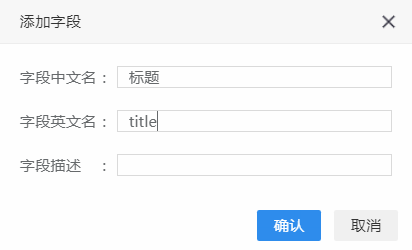
点击确认
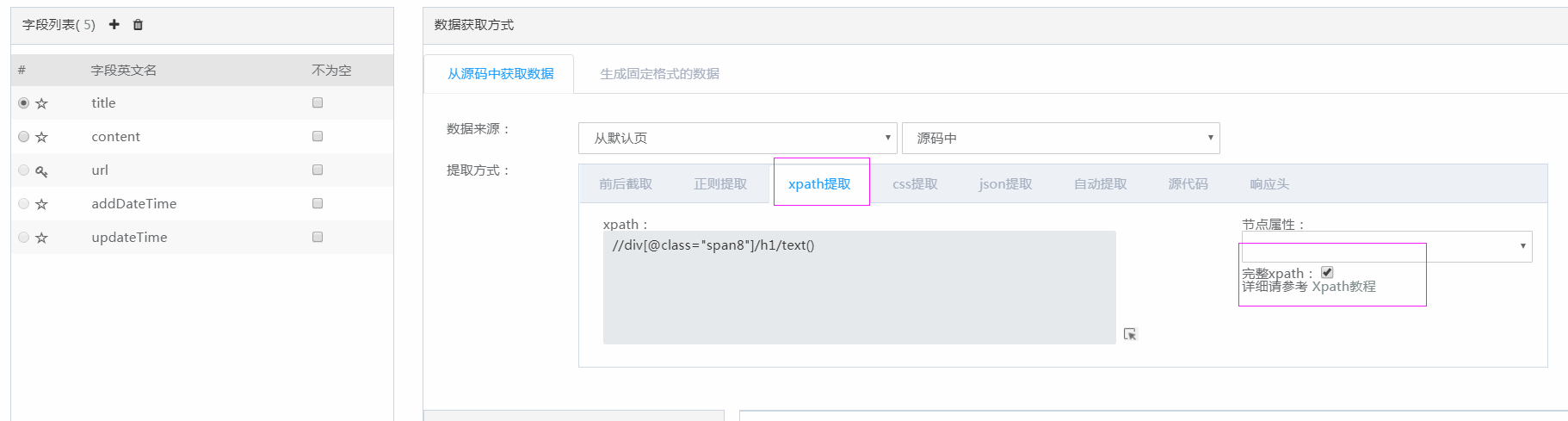
选择xpath提取,勾选 完整xpath后面的那个复选框,在作文页面标题部分右击检查,即可配置如图xpath路径,将两个字段配置完成之后点击页面下方保存按钮,再点击完成,到这里这个爬虫就已经配置完成,我们可以点击启动,运行出结果之后就可以在爬取结果中看见我们爬到的数据了。