网页中存在要展示的内容分多页显示,其中不仅包含列表页还有内容页都存在类似的情况;其中列表页分页最为常见,其中列表页分页可能包含:“下一页”和“瀑布流分页”;内容页分页可能包含:“首页全部列出”和“上下页模式”。其实列表页和内容页的处理目标不同,列表页是获得url集合,而内容页是请求多页url,并将请求后响应结果合并在一起,构成完整内容页内容。下面分别介绍以上几种情况的平台配置方法。
列表页:“下一页”
实例网站:安徽省高级人民法院
获取内容:获取全部内容页链接

步骤:
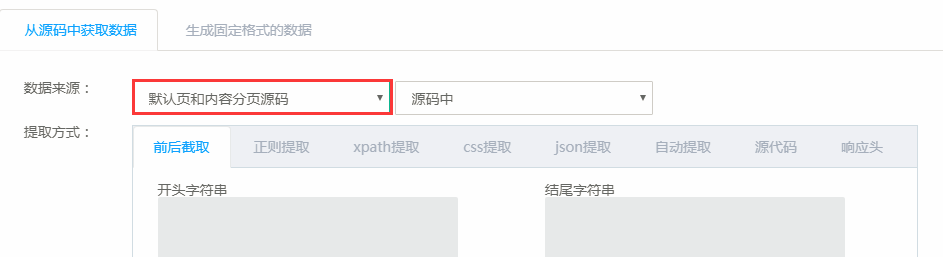
在采集器模式,“网页采集规则”中配置要抓取的链接,在这里面配置(如下图所示)中抓取当页的url和下一页url,抓取后url会存储到任务此次运行使用redis队列中,所以下一页url再作为种子url去抓取当页url和下一页url,以此类推所有分页url都能得到提取。
列表页:“瀑布流分页”
实例网站:今日头条首页
获取内容:获取全部内容页链接
说明:今日头条首页是列表页是典型的“瀑布流分页”,即没有“下一页”字样,都是靠鼠标往下滚动进行翻页。
步骤:
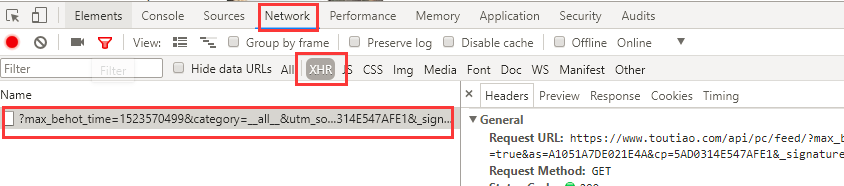
(1) 抓包:浏览器F12->Network->XHR
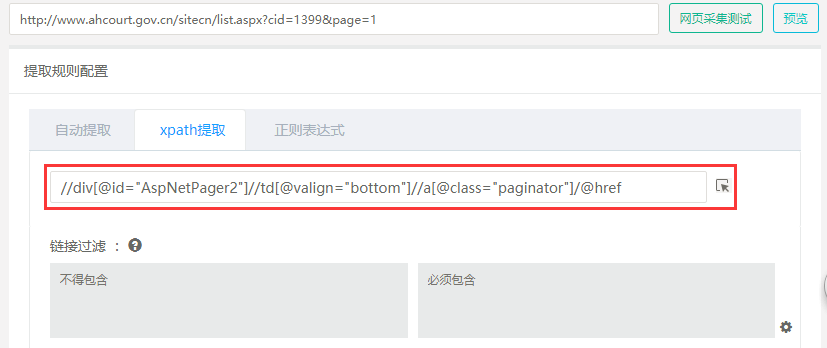
(1) 这类分页,下一页url的构造要素一般都在上一页返回的json中,这种情况获得当页内容页url和下一页url的方法有两种:
在网页采集规则页面配置两个url 正则配置项,这两个配置项要能适配同一个url;一个配置项用于通过正则方式获得内容页url,另一个配置项用于获得下一页url。
只配置一个url正则配置项,在其中通过正则表达式获取全部响应结果,然后再通过“请求后插件”进行解析提取当页内容页url和构造下一页url。
内容页:“首页全部列出”和“上下页模式”
这类比较简单,就不举具体的实例。
步骤:
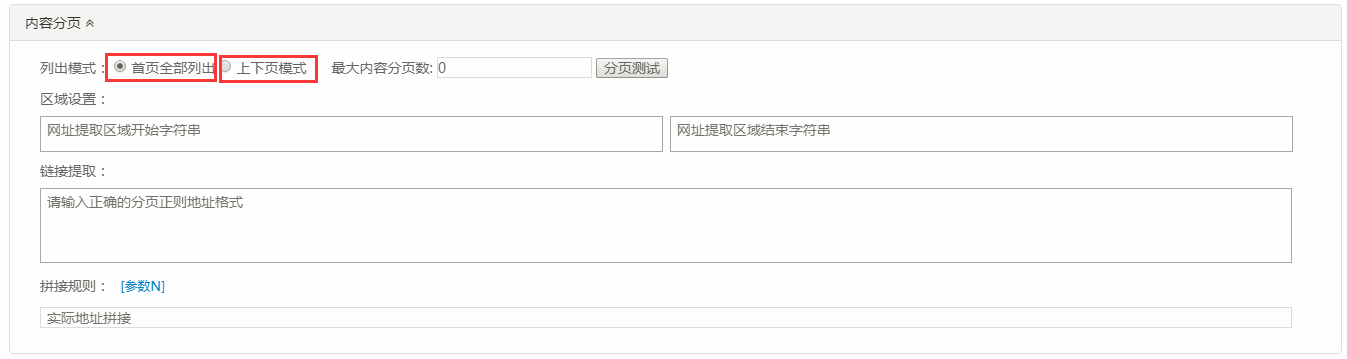
(1) 采集器模式的内容采集规则,对如下所示的部分进行按需填写。
(1) 当(1)设置完成之后,需要设置具体字段进行解析,具体选择如下图所示。